#include<bits/stdc++.h> usingnamespace std; constint MAX = 1e6 + 7; constint MAXN = 1e3 + 7; #define int long long int L[MAXN], R[MAXN], sum[MAXN], tag[MAXN]; int block[MAX], num[MAX]; int n, m, M, sqr; int mode; voidpre() { sqr = sqrt(n); m = n / sqr; for (int i = 1; i <= n; i++) { block[i] = (i - 1) / sqr + 1; sum[block[i]] += num[i]; } for (int i = 1; i <= m; i++) { L[i] = (i - 1) * sqr + 1; R[i] = i * sqr; }
if (n % sqr) { L[m + 1] = R[m] + 1; R[m + 1] = n; } } intcheck_2(int l, int r) { int res = 0; if ((r - l + 1) > ((R[block[l]] - L[block[l]] + 1) >> 1)) { res = sum[block[l]]; for (int i = L[block[l]]; i < l; i++) res -= num[i] + tag[block[i]]; for (int i = r + 1; i <= R[block[l]]; i++) res -= num[i] + tag[block[i]]; } else { for (int i = l; i <= r; i++) { res += num[i] + tag[block[i]]; } } return res; } intcheck(int l, int r) { int res = 0; if (block[l] == block[r]) { res = check_2(l, r); } else { res += check_2(l, R[block[l]]); res += check_2(L[block[r]], r); for (int i = block[l] + 1; i < block[r]; i++) { res += sum[i]; } } return res; } voidupdate_2(int l, int r, int v) { if ((r - l + 1) > (R[block[l]] - L[block[l]] + 1) >> 1) { for (int i = L[block[l]]; i < l; i++) { num[i] -= v; } for (int i = R[block[l]]; i > r; i--) { num[i] -= v; } tag[block[l]] += v; } else { for (int i = l; i <= r; i++) { num[i] += v; } } sum[block[l]] += v * (r - l + 1); } voidupdate_1(int l, int r, int v) { if (block[l] == block[r]) { update_2(l, r, v); } else { update_2(l, R[block[l]], v); update_2(L[block[r]], r, v); for (int i = block[l] + 1; i < block[r]; i++) { tag[i] += v; sum[i] += v * (R[i] - L[i] + 1); } } } signedmain() { return0; }
#include<bits/stdc++.h> usingnamespace std; constint MAX = 200007; int N, M, tree[MAX]; intlowbit(int x) { return x & (-x); } voidupdate(int x, int k) { while (x <= N) { tree[x] += k; x += lowbit(x); } } intquery(int x) { int res = 0; while (x > 0) { res += tree[x]; x -= lowbit(x); } return res; } intread() { int bj = 0, num = 0; char ch = getchar(); while (!isdigit(ch)) { if (ch == '-') { bj = 1; } ch = getchar(); } while (isdigit(ch)) { num = num * 10 + ch - '0'; ch = getchar(); } return bj ? -num : num; } intmain() { int T = read(); for (int j = 1; j <= T; j++) { memset(tree, 0, sizeof(tree)); N = read(); for (int i = 1; i <= N; i++) { int num = read(); update(i, num); } string s; cout << "Case " << j << ":" << endl; while (cin >> s && s != "End") { if (s == "Add") { int p = read(); int num = read(); update(p, num); } if (s == "Sub") { int p = read(); int num = read(); update(p, -num); } if (s == "Query") { int fr = read(); int to = read(); cout << query(to) - query(fr - 1) << endl; } } } }
intrankk(int l, int r, int k) { vector<pair<int, int>> v;//开vector! IT it2 = split(r + 1), it1 = split(l);//分出左右界 v.clear(); for (IT i = it1; i != it2; i++) { int l = i->l, r = i->r, val = i->val; v.push_back(make_pair(val, r - l + 1)); //权值val,以及“以val为权值的区间”里的单点个数 } sort(v.begin(), v.end()); //violence!!! for (VIT i = v.begin(); i != v.end(); i++) { k -= i->second; //跑过一个元素 if (k <= 0)//跑过头,也就是找到了 return i->first; } return-1; }
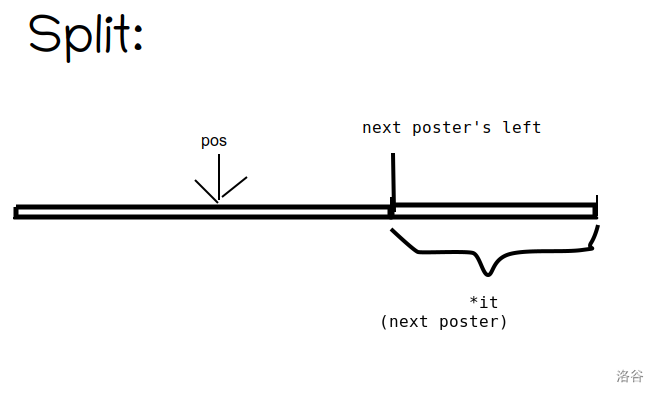
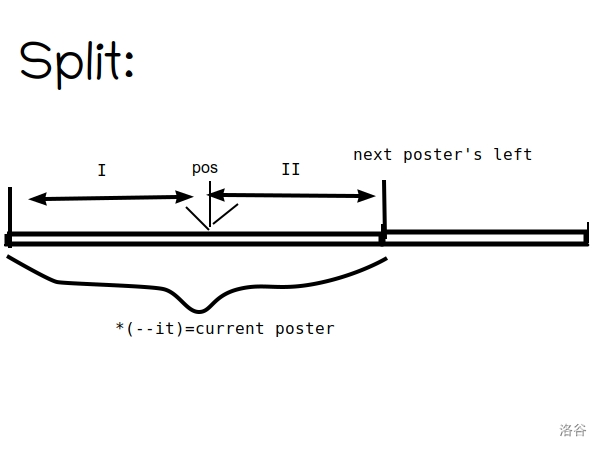
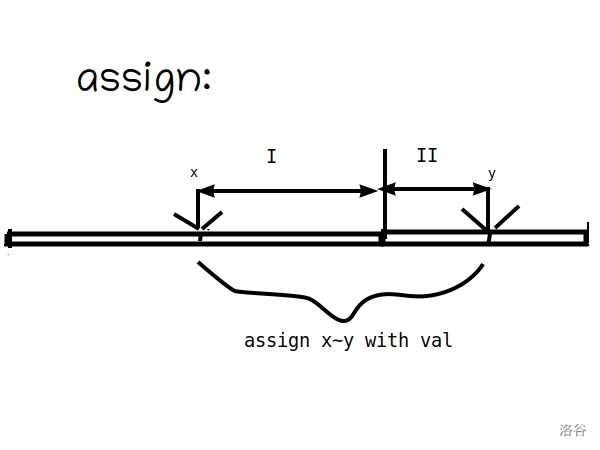
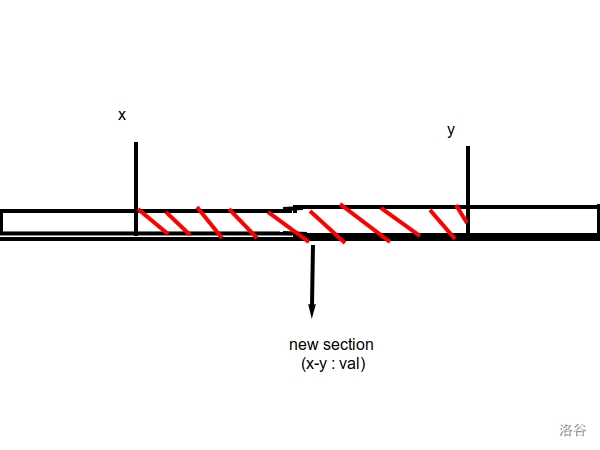
#include<bits/stdc++.h> usingnamespace std; #define IT set<node>::iterator #define VIT vector<pair<int, int>>::iterator #define int long long structnode { int l, r; mutableint val; node(int a, int b, int c) { l = a, r = b, val = c; } booloperator<(const node a) const { return l < a.l; } }; set<node> s; int MOD; int n, m, seed, vmax; IT split(int pos) { IT it = s.lower_bound(node(pos, 0, 0)); if (it != s.end() && it->l == pos) { return it; } it--; int l = it->l, r = it->r, val = it->val; s.erase(it); s.insert(node(l, pos - 1, val)); return s.insert(node(pos, r, val)).first; } voidassign(int l, int r, int val) { IT it2 = split(r + 1), it1 = split(l); s.erase(it1, it2); s.insert(node(l, r, val)); } voidupdate(int l, int r, int k) { IT it2 = split(r + 1), it1 = split(l); for (IT i = it1; i != it2; i++) { i->val += k; } } intrankk(int l, int r, int k) { vector<pair<int, int>> v; IT it2 = split(r + 1), it1 = split(l); v.clear(); for (IT i = it1; i != it2; i++) { int l = i->l, r = i->r, val = i->val; v.push_back(make_pair(val, r - l + 1)); } sort(v.begin(), v.end()); for (VIT i = v.begin(); i != v.end(); i++) { k -= i->second; if (k <= 0) return i->first; } return-1; } intquick_pow(int a, int exp) { if (exp == 1) { return a % MOD; } int tmp = quick_pow(a, exp / 2); if (exp % 2 == 0) { return (tmp * tmp) % MOD; } else { return ((tmp * tmp) % MOD * a) % MOD; } } intpowsum(int l, int r, int exp) { IT it2 = split(r + 1), it1 = split(l); int res = 0; for (IT i = it1; i != it2; i++) { int l = i->l, r = i->r, val = i->val; res = (res + (r - l + 1) * quick_pow(val % MOD, exp) % MOD) % MOD; } return res; } inlineintrnd() { int ret = seed; seed = (seed * 7 + 13) % 1000000007; return ret; } signedmain() { scanf("%lld%lld%lld%lld", &n, &m, &seed, &vmax); for (int i = 1; i <= n; i++) { int num = rnd() % vmax + 1; s.insert(node(i, i, num)); }
for (int i = 1; i <= m; i++) { int op = (rnd() % 4) + 1; int l = (rnd() % n) + 1; int r = (rnd() % n) + 1; if (l > r) swap(l, r); int x; if (op == 3) { x = (rnd() % (r - l + 1)) + 1; } else x = (rnd() % vmax) + 1; if (op == 4) { MOD = (rnd() % vmax) + 1; } if (op == 1) { update(l, r, x); } if (op == 2) { assign(l, r, x); } if (op == 3) { cout << rankk(l, r, x) << endl; } if (op == 4) { cout << powsum(l, r, x) << endl; } } return0; }